Sensing Matrices
Contents
19.1. Sensing Matrices#
19.1.1. Matrices Satisfying RIP#
This section provides basic results about construction of matrices which can satisfy restricted isometry property.
The goal of designing an \(M \times N\) sensing matrix involves:
Stable embedding for signals with has high sparsity as possible (high \(K\))
As few measurements as possible (low \(M\))
There are two different approaches
Deterministic approach
Randomized approach
Known deterministic approaches so far tend to require \(M\) to be very large(\(O(K^2 \ln N)\) or \(O(KN^{\alpha}\)). We can overcome this limitation by randomizing matrix construction.
Construction process:
Input \(M\) and \(N\).
Generate \(\Phi\) by choosing \(\Phi_{i j}\) as independent realizations from some probability distribution.
Suppose that \(\Phi\) is drawn from normal distribution.
It can be shown that the rank of \(\Phi\) is \(M\) with probability \(1\).
Example 19.1 (Random matrices are full rank.)
We can verify this fact by doing a small computer simulation.
M = 6;
N = 20;
trials = 10000;
numFullRankMatrices = 0;
for i=1:trials
% Create a random matrix of size M x N
A = rand(M,N);
% Obtain its rank
R = rank(A);
% Check whether the rank equals M or not
if R == M
numFullRankMatrices = numFullRankMatrices + 1;
end
end
fprintf('Number of trials: %d\n',trials);
fprintf('Number of full rank matrices: %d\n',numFullRankMatrices);
percentage = numFullRankMatrices*100/trials;
fprintf('Percentage of full rank matrices: %.2f %%\n', percentage);
This program generates a number of random matrices and measures their ranks. It verifies whether they are full rank or not.
Here is a sample output:
>> demoRandomMatrixRank
Number of trials: 10000
Number of full rank matrices: 10000
Percentage of full rank matrices: 100.00
Thus if we choose \(M=2K\), any subset of \(2K\) columns will be linearly independent. Thus the matrix with satisfy RIP with some \(\delta_{2K} > 0\). But this construction doesn’t tell us exact value of \(\delta_{2K}\). In order to find out \(\delta_{2K}\), we must consider all possible \(K\)-dimensional subspaces of \(\RR^N\). This is computationally impossible for reasonably large \(N\) and \(K\). What is the alternative?
We can start with a chosen value of \(\delta_{2K}\) and try to construct a matrix which matches it.
Before we proceed further, we should take a detour and review sub-Gaussian distributions in Subgaussian Distributions.
We now state the main theorem of this section.
Theorem 19.1 (Norm bounds on subgaussian vectors)
Suppose that \(X = [X_1, X_2, \dots, X_M]\) where each \(X_i\) is i.i.d. with \(X_i \sim \Sub (c^2)\) and \(\EE (X_i^2) = \sigma^2\). Then
Moreover, for any \(\alpha \in (0,1)\) and for any \(\beta \in [c^2/\sigma^2, \beta_{\text{max}}\), there exists a constant \(\kappa^* \geq 4\) depending only on \(\beta_{\text{max}}\) and the ratio \(\sigma^2/c^2\) such that
and
19.1.1.1. Conditions on Random Distribution for RIP#
Let us get back to our business of constructing a matrix \(\Phi\) using random distributions which satisfies RIP with a given \(\delta\). We will impose some conditions on the random distribution.
We require that the distribution will yield a matrix that is norm-preserving. This requires that
(19.1)#\[\EE (\Phi_{i j}^2) = \frac{1}{M}\]Hence variance of distribution should be \(\frac{1}{M}\).
We require that distribution is a sub-Gaussian distribution; i.e., there exists a constant \(c > 0\) such that
(19.2)#\[ \EE(\exp(\Phi_{i j} t)) \leq \exp \left (\frac{c^2 t^2}{2} \right )\]
This says that the moment generating function of the distribution
is dominated by a Gaussian distribution.
In other words, tails of the distribution decay at least as fast as the tails of a Gaussian distribution.
We will further assume that entries of \(\Phi\) are strictly sub-Gaussian. i.e., they must satisfy (19.2) with
\[ c^2 = \EE (\Phi_{i j}^2) = \frac{1}{M}. \]
Under these conditions we have the following result.
Corollary 19.1 (Norm bounds on subgaussian matrix vector product)
Suppose that \(\Phi\) is an \(M\times N\) matrix whose entries \(\Phi_{i j}\) are i.i.d. with \(\Phi_{i j}\) drawn according to a strictly sub-Gaussian distribution with \(c^2 = \frac{1}{M^2}\).
Let \(Y = \Phi x\) for \(x \in \RR^N\). Then for any \(\epsilon > 0\) and any \(x \in \RR^N\),
and
where \(\kappa^* = \frac{2}{1 - \ln(2)} \approx 6.5178\).
This means that the norm of a sub-Gaussian random vector strongly concentrates about its mean.
19.1.1.2. Sub Gaussian Matrices satisfy the RIP#
Using this result we now state that sub-Gaussian matrices satisfy the RIP.
Theorem 19.2 (Lower bound on required number of measurements)
Fix \(\delta \in (0,1)\). Let \(\Phi\) be an \(M\times N\) random matrix whose entries \(\Phi_{i j}\) are i.i.d. with \(\Phi_{i j}\) drawn according to a strictly sub-Gaussian distribution with \(c^2 = \frac{1}{M}\). If
then \(\Phi\) satisfies the RIP of order \(K\) with the prescribed \(\delta\) with probability exceeding \(1 - 2e^{-\kappa_2 M}\), where \(\kappa_1\) is arbitrary and
We note that this theorem achieves \(M\) of the same order as the lower bound obtained in Theorem 18.42 up to a constant.
This is much better than deterministic approaches.
19.1.1.3. Advantages of Random Construction#
There are a number of advantages of the random sensing matrix construction approach:
One can show that for random construction, the measurements are democratic. This means that all measurements are equal in importance and it is possible to recover the signal from any sufficiently large subset of the measurements.
Thus by using random \(\Phi\) one can be robust to the loss of loss or corruption of a small fraction of measurements.
In general we are more interested in \(x\) which is sparse in some basis \(\Psi\). In this setting, we require that \(\Phi \Psi\) satisfy the RIP.
Deterministic construction would explicitly require taking \(\Psi\) into account.
But if \(\Phi\) is random, we can avoid this issue.
If \(\Phi\) is Gaussian and \(\Psi\) is an orthonormal basis, then one can easily show that \(\Phi \Psi\) will also have a Gaussian distribution.
Thus if \(M\) is high, \(\Phi \Psi\) will also satisfy RIP with very high probability.
Similar results hold for other sub-Gaussian distributions as well.
19.1.2. Rademacher Sensing Matrices#
In this subsection, we collect several results related to Rademacher sensing matrices.
Definition 19.1
A Rademacher sensing matrix \(\Phi \in \RR^{M \times N}\) with \(M < N\) is constructed by drawing each entry \(\phi_{i j}\) independently from a Rademacher random distribution given by
Thus \(\phi_{i j}\) takes a value \(\pm \frac{1}{\sqrt{M}}\) with equal probability.
We can remove the scale factor \(\frac{1}{\sqrt{M}}\) out of the matrix \(\Phi\) writing
With that we can draw individual entries of \(\Chi\) from a simpler Rademacher distribution given by
Thus entries in \(\Chi\) take values of \(\pm 1\) with equal probability.
This construction is useful since it allows us to implement the multiplication with \(\Phi\) in terms of just additions and subtractions. The scaling can be implemented towards the end in the signal processing chain.
We note that
Actually we have a better result with
We can write
where \(\phi_j \in \RR^M\) is a Rademacher random vector with independent entries. We note that
In this case we also have
Thus the squared length of each of the columns in \(\Phi\) is \(1\).
Lemma 19.1
Let \(\bz \in \RR^M\) be a Rademacher random vector with i.i.d entries \(z_i\) that take a value \(\pm \frac{1}{\sqrt{M}}\) with equal probability. Let \(\bu \in \RR^M\) be an arbitrary unit norm vector. Then
Representative values of this bound are plotted below.
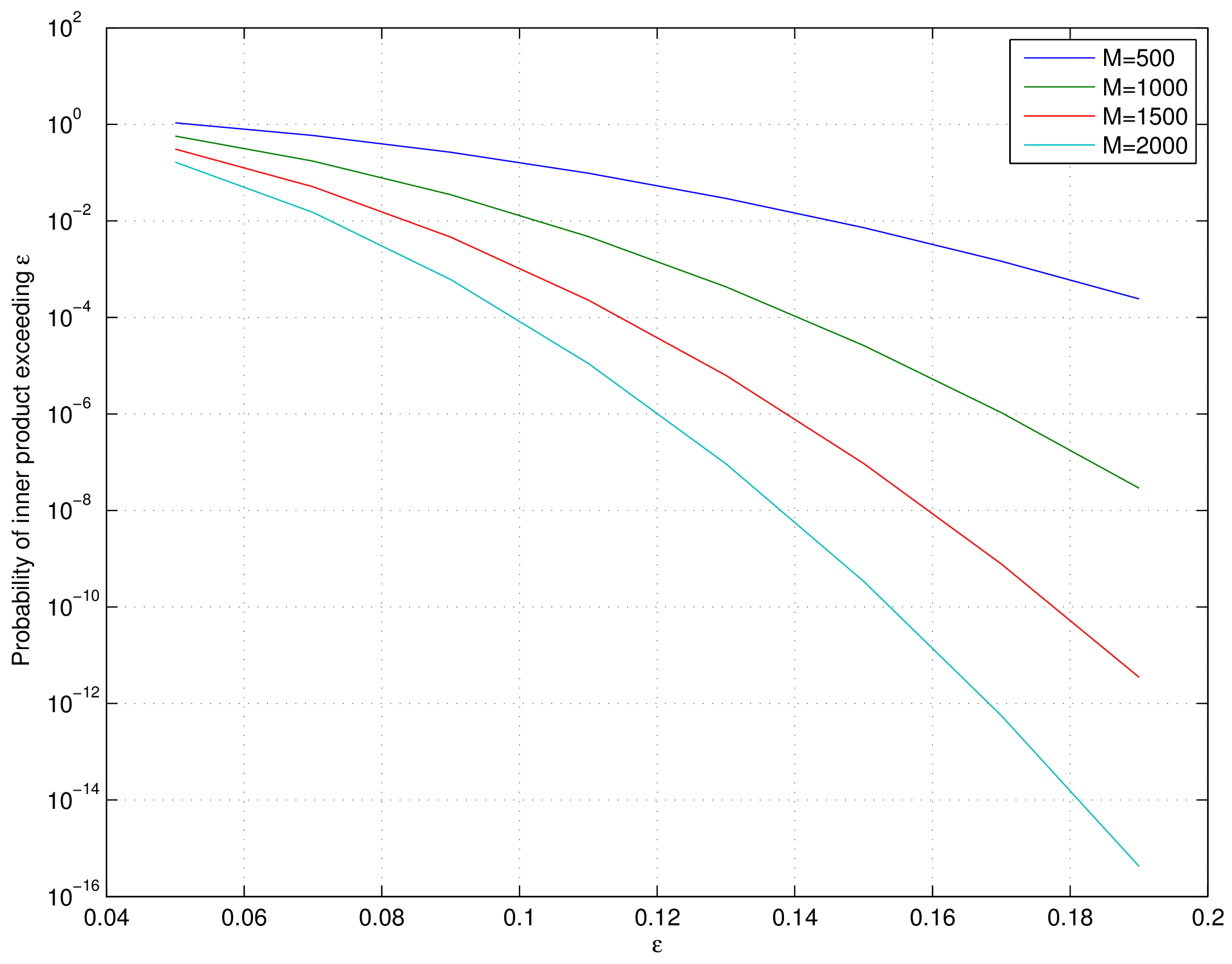
Fig. 19.1 Tail bound for the probability of inner product of a Rademacher random vector with a unit norm vector#
Proof. This can be proven using Hoeffding’s inequality. To be elaborated later.
A particular application of this lemma is when \(\bu\) itself is another (independently chosen) unit norm Rademacher random vector.
The lemma establishes that the probability of inner product of two independent unit norm Rademacher random vectors being large is very very small. In other words, independently chosen unit norm Rademacher random vectors are incoherent with high probability. This is a very useful result as we will see later in measurement of coherence of Rademacher sensing matrices.
19.1.2.1. Joint Correlation#
Columns of \(\Phi\) satisfy a joint correlation property ([80]) which is described in following lemma.
Lemma 19.2
Let \(\{\bu_k\} \) be a sequence of \(K\) vectors (where \(\bu_k \in \RR^M\)) whose \(\ell_2\) norms do not exceed one. Independently choose \(\bz \in \RR^M\) to be a random vector with i.i.d. entries \(z_i\) that take a value \(\pm \frac{1}{\sqrt{M}}\) with equal probability. Then
Proof. Let us call \(\gamma = \max_{k} | \langle \bz, \bu_k\rangle |\).
We note that if for any \(\bu_k\), \(\| \bu_k \|_2 <1\) and we increase the length of \(\bu_k\) by scaling it, then \(\gamma\) will not decrease and hence \(\PP(\gamma \leq \epsilon)\) will not increase.
Thus if we prove the bound for vectors \(\bu_k\) with \(\| \bu_k\|_2 = 1 \Forall 1 \leq k \leq K\), it will be applicable for all \(\bu_k\) whose \(\ell_2\) norms do not exceed one.
Hence we will assume that \(\| \bu_k \|_2 = 1\).
From Lemma 19.1 we have
\[ \PP \left ( | \langle z, u_k \rangle | > \epsilon \right ) \leq 2 \exp \left (- \epsilon^2 \frac{M}{2} \right ). \]Now the event
\[ \left \{ \max_{k} | \langle z, u_k\rangle | > \epsilon \right \} = \bigcup_{ k= 1}^K \{| \langle z, u_k\rangle | > \epsilon\} \]i.e. if any of the inner products (absolute value) is greater than \(\epsilon\) then the maximum is greater.
We recall Boole’s inequality which states that
\[ \PP \left(\bigcup_{i} A_i \right) \leq \sum_{i} \PP(A_i). \]Thus
\[ \PP\left(\max_{k} | \langle \bz, \bu_k\rangle | > \epsilon \right) \leq 2 K \exp \left (- \epsilon^2 \frac{M}{2} \right ). \]This gives us
\[\begin{split} \PP\left(\max_{k} | \langle \bz, \bu_k\rangle | \leq \epsilon \right) &= 1 - \PP\left(\max_{k} | \langle \bz, \bu_k\rangle | > \epsilon \right) \\ &\geq 1 - 2 K \exp \left(- \epsilon^2 \frac{M}{2} \right). \end{split}\]
19.1.2.2. Coherence#
We show that coherence of Rademacher sensing matrix is fairly small with high probability (adapted from [80]).
Lemma 19.3
Fix \(\delta \in (0,1)\). For an \(M \times N\) Rademacher sensing matrix \(\Phi\) as defined in Definition 19.1, the coherence statistic
with probability exceeding \(1 - \delta\).
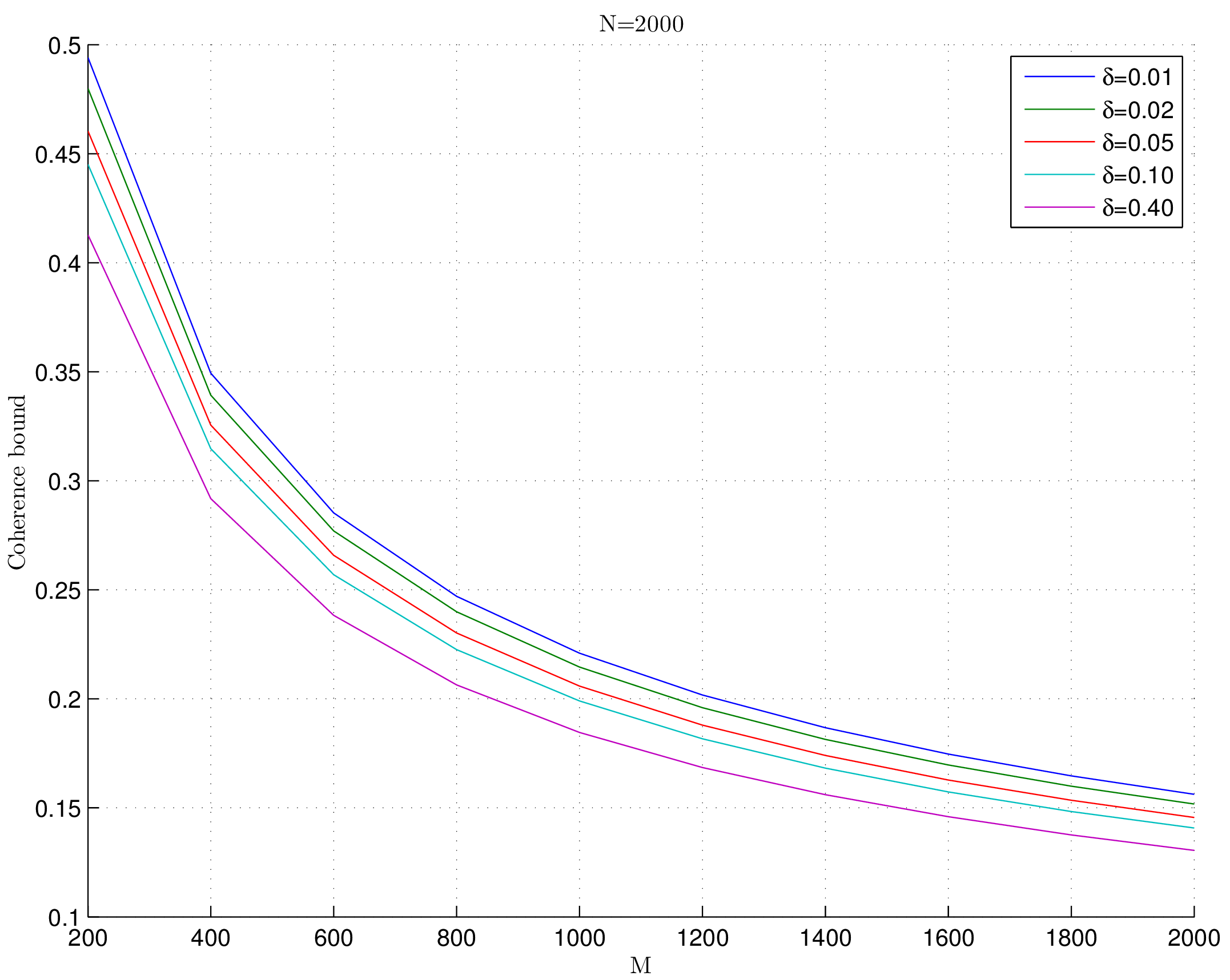
Fig. 19.2 Coherence bounds for Rademacher sensing matrices#
Proof. We recall the definition of coherence as
Since \(\Phi\) is a Rademacher sensing matrix hence each column of \(\Phi\) is unit norm column.
Consider some \(1 \leq j < k \leq N\) identifying columns \(\phi_j\) and \(\phi_k\).
We note that they are independent of each other.
Thus from Lemma 19.1 we have
\[ \PP \left ( |\langle \phi_j, \phi_k \rangle | > \epsilon \right ) \leq 2 \exp \left (- \epsilon^2 \frac{M}{2} \right ). \]Now there are \(\frac{N(N-1)}{2}\) such pairs of \((j, k)\).
Hence by applying Boole’s inequality
\[ \PP \left ( \underset{j < k} {\max} |\langle \phi_j, \phi_k \rangle | > \epsilon \right ) \leq 2 \frac{N(N-1)}{2} \exp \left (- \epsilon^2 \frac{M}{2} \right ) \leq N^2 \exp \left (- \epsilon^2 \frac{M}{2} \right ). \]Thus we have
\[ \PP \left ( \mu > \epsilon \right ) \leq N^2 \exp \left (- \epsilon^2 \frac{M}{2} \right ). \]What we need to do now is to choose a suitable value of \(\epsilon\) so that the R.H.S. of this inequality is simplified.
We choose
\[ \epsilon^2 = \frac{4}{M} \ln \left ( \frac{N}{\delta}\right ). \]This gives us
\[ \epsilon^2 \frac{M}{2} = 2 \ln \left ( \frac{N}{\delta}\right ) \implies \exp \left (- \epsilon^2 \frac{M}{2} \right ) = \left ( \frac{\delta}{N} \right)^2. \]Putting back we get
\[ \PP \left ( \mu > \epsilon \right )\leq N^2 \left ( \frac{\delta}{N} \right)^2 \leq \delta^2. \]This justifies why we need \(\delta \in (0,1)\).
Finally
\[ \PP \left ( \mu \leq \sqrt{ \frac{4}{M} \ln \left( \frac{N}{\delta}\right)} \right ) = \PP (\mu \leq \epsilon) = 1 - \PP (\mu > \epsilon) > 1 - \delta^2 \]and
\[ 1 - \delta^2 > 1 - \delta \]which completes the proof.
19.1.3. Gaussian Sensing Matrices#
In this subsection we collect several results related to Gaussian sensing matrices.
Definition 19.2
A Gaussian sensing matrix \(\Phi \in \RR^{M \times N}\) with \(M < N\) is constructed by drawing each entry \(\phi_{i j}\) independently from a Gaussian random distribution \(\Gaussian(0, \frac{1}{M})\).
We note that
We can write
where \(\phi_j \in \RR^M\) is a Gaussian random vector with independent entries. We note that
Thus the expected value of squared length of each of the columns in \(\Phi\) is \(1\).
19.1.3.1. Joint Correlation#
Columns of \(\Phi\) satisfy a joint correlation property ([80]) which is described in following lemma.
Lemma 19.4
Let \(\{\bu_k\} \) be a sequence of \(K\) vectors (where \(\bu_k \in \RR^M\)) whose \(\ell_2\) norms do not exceed one. Independently choose \(\bz \in \RR^M\) to be a random vector with i.i.d. \(\Gaussian(0, \frac{1}{M})\) entries. Then
Proof. Let us call \(\gamma = \max_{k} | \langle \bz, \bu_k\rangle |\).
We note that if for any \(\bu_k\), \(\| \bu_k \|_2 <1 \) and we increase the length of \(\bu_k\) by scaling it, then \(\gamma\) will not decrease and hence \(\PP(\gamma \leq \epsilon)\) will not increase.
Thus if we prove the bound for vectors \(\bu_k\) with \(\| \bu_k\|_2 = 1 \Forall 1 \leq k \leq K\), it will be applicable for all \(\bu_k\) whose \(\ell_2\) norms do not exceed one.
Hence we will assume that \(\| \bu_k \|_2 = 1\).
Now consider \(\langle \bz, \bu_k \rangle\).
Since \(\bz\) is a Gaussian random vector, hence \(\langle \bz, \bu_k \rangle\) is a Gaussian random variable.
Since \(\| \bu_k \| =1\) hence
\[ \langle \bz, \bu_k \rangle \sim \Gaussian \left(0, \frac{1}{M} \right). \]We recall a well known tail bound for Gaussian random variables which states that
\[ \PP_X ( | x | > \epsilon) \; = \; \sqrt{\frac{2}{\pi}} \int_{\epsilon \sqrt{N}}^{\infty} \exp \left( -\frac{x^2}{2}\right) d x \; \leq \; \exp \left (- \epsilon^2 \frac{M}{2} \right). \]Now the event
\[ \left \{ \max_{k} | \langle \bz, \bu_k\rangle | > \epsilon \right \} = \bigcup_{ k= 1}^K \{| \langle \bz, \bu_k\rangle | > \epsilon\} \]i.e. if any of the inner products (absolute value) is greater than \(\epsilon\) then the maximum is greater.
We recall Boole’s inequality which states that
\[ \PP \left(\bigcup_{i} A_i \right) \leq \sum_{i} \PP(A_i). \]Thus
\[ \PP\left(\max_{k} | \langle \bz, \bu_k\rangle | > \epsilon \right) \leq K \exp \left(- \epsilon^2 \frac{M}{2} \right). \]This gives us
\[\begin{split} \begin{aligned} \PP\left(\max_{k} | \langle \bz, \bu_k\rangle | \leq \epsilon \right) &= 1 - \PP\left(\max_{k} | \langle \bz, \bu_k\rangle | > \epsilon \right) \\ &\geq 1 - K \exp \left(- \epsilon^2 \frac{M}{2} \right). \end{aligned} \end{split}\]